Publicado en Open Citation blog
https://opencitations.hypotheses.org/3499
Un nuevo flujo de trabajo revolucionario para una colección unificada de citas: salude al Índice OpenCitations
Blog de Ivan Heibi (Universidad de Bolonia), Arianna Moretti (Universidad de Bolonia) y Chiara Di Giambattista (Universidad de Bolonia).
En los últimos cinco años, los datos de OpenCitations se han enriquecido con numerosos índices nuevos de datos de citas abiertas procedentes de distintas fuentes. Sin embargo, la cantidad y diversificación de la información ingerida han planteado varios problemas, que recientemente han hecho imprescindible una revisión completa del flujo de trabajo de ingesta. El resultado ha sido una revolución en la forma de entregar los datos de OpenCitations. En esta entrada de blog, explicaremos el contexto y los retos planteados por el antiguo procedimiento. A continuación, presentaremos el nuevo flujo de trabajo de ingestión, diseñado para producir sólo dos colecciones completas: OpenCitations Index, que recoge los datos de citas en abierto, y OpenCitations Meta, para los metadatos bibliográficos en abierto.
Érase una vez, había cinco índices OpenCitations....
En 2018, OpenCitations lanzó la versión de lanzamiento de su primer índice de citas, COCI (citas de Crossref), que contenía alrededor de 300 millones de enlaces de citas derivados del subconjunto de las listas de referencias de la base de datos de Crossref, donde las entidades citantes y citadas se identificaron utilizando identificadores de objetos digitales (DOI). COCI reunía citas con metadatos asociados en cumplimiento de las recomendaciones de la Initiative for Open Citations (I4OC) de que los datos de las citas debían ser estructurados, separables y abiertos, marcando así un punto de inflexión al ofrecer una alternativa disruptiva y gratuita a fuentes anteriores como Google Scholar, que proporcionaba datos de libre acceso aunque no descargables, y Web of Science o Scopus, que exigían un acceso de pago.
En poco tiempo, COCI se convirtió en un índice de datos de citas competitivo y de confianza, utilizado por numerosos repositorios institucionales, entre ellos B!son y Optimeta. En 2021, COCI fue tenido en cuenta en un estudio comparativo con las fuentes más relevantes del panorama, incluidas las propietarias, que mostró que su cobertura se acercaba a la paridad con las de las otras fuentes implicadas en el análisis (Microsoft Academic, Scopus, Dimensions y Web of Science). En el momento de su actualización más reciente, en enero de 2023, COCI contaba con más de 1.400 millones de citas. La razón de esta cifra excepcional radica en varios factores, entre ellos la adhesión de Elsevier a la Declaración sobre la Evaluación de la Investigación (DORA) en diciembre de 2020, que condujo a la publicación abierta a través de Crossref de las listas de referencias de los artículos publicados en todas sus revistas, y confirmó el valor de iniciativas como la Iniciativa para las Citas Abiertas (I4OC).
Sin embargo, antes de este cambio de opinión, en 2019 OpenCitations había intentado reducir la brecha de cobertura de citas abiertas lanzando su segundo índice, el Crowdsourced Open Citations Index (CROCI). Este índice permitía a los editores y académicos contribuir directamente cargando citas abiertas crowdsourced en la infraestructura de OpenCitations.
En diciembre de 2022, se dio un nuevo paso concreto hacia una pluralidad fáctica de índices OpenCitations mediante la incorporación de nuevas fuentes de datos a la infraestructura, con la publicación de los repositorios inaugurales de DOCI (citas de DataCite) y POCI (citas de PubMed). En junio de 2023, también se publicó la primera versión del repositorio OROCI (citas de OpenAIRE), y se espera que JOCI (citas de JALC) esté disponible a finales de noviembre de 2023, para un total de cinco colecciones de diferentes fuentes.
¿Por qué un nuevo flujo de trabajo? Los problemas de la gestión de múltiples fuentes y los nuevos retos
Aunque disponer de tal variedad y riqueza de índices ayudó a presentar la amplitud de las fuentes de OpenCitations, el reciente aumento del número de fuentes y la diversificación de los datos integrados dieron lugar a dos problemas principales:
la necesidad de gestionar la introducción de nuevos tipos de identificadores en una infraestructura de software basada en DOI, y
la consiguiente posibilidad de encontrar la misma cita expresada por varias fuentes con diferentes identificadores.
Además, pronto se hizo evidente la necesidad de optimizar la reutilización de los componentes de software ya desarrollados para facilitar los procesos de cruce de metadatos entre los modelos de datos de las nuevas fuentes y el modelo de datos de OpenCitations, con el objetivo de definir un flujo de trabajo funcional y fácilmente ampliable para ser reutilizado fácilmente a la hora de incorporar nuevas fuentes de datos, que debería ser:
lo suficientemente genérico como para establecer un procedimiento único a nivel mundial;
suficientemente personalizable para capturar la información necesaria dentro de cada uno de los modelos y formatos de datos específicos.
Como solución, decidimos utilizar OpenCitations Meta, la nueva base de datos y herramienta de OpenCitations para la gestión de datos bibliográficos relacionados con las publicaciones implicadas en las citas. OpenCitations Meta permite asignar a cada entidad implicada en una cita un identificador interno, nominalmente el OpenCitations Meta Identifier (OMID), al que se redirigen todos los identificadores persistentes asociados de la misma publicación.
Como resultado, la asignación de un OMID para cada recurso bibliográfico también permitió la identificación inequívoca de cada cita, independientemente del esquema de identificador persistente utilizado originalmente por la fuente de datos para identificar los recursos. Este enfoque nos permitió realizar la deduplicación de datos y, finalmente, hacer converger todas las contribuciones de las fuentes en un índice unificado que contiene todas las citas únicas gestionadas por OpenCitations, expresadas como enlaces de citas OMID a OMID.
El flujo de trabajo revisado
El nuevo flujo de trabajo se basa en tres componentes principales con la ventaja de optimizar el proceso tanto en términos de coste computacional como de flexibilidad. Como se muestra en la Fig. 1, en un paso preliminar, el software específico de la fuente convierte el conjunto de datos de entrada -estructurado de acuerdo con el modelo de datos de la fuente- para extraer dos colecciones de datos compatibles con el modelo de datos OpenCitations en formato tabular para los metadatos bibliográficos y los datos de citas, respectivamente.
Los siguientes pasos son comunes al proceso de cada conjunto de datos.
PASO 1: La colección de metadatos bibliográficos se utiliza como entrada para el software META. En esta fase, se comprueba si las entidades bibliográficas se han integrado previamente en nuestra infraestructura (procedentes de otras fuentes de datos). En caso afirmativo, el OMID existente se vincula también a los nuevos identificadores alternativos de los nuevos recursos bibliográficos. Los nuevos valores de metadatos, si los hay, también se integran. Se produce un nuevo identificador OMID para entidades nunca encontradas anteriormente, que representa de forma única el recurso bibliográfico en OpenCitations. Los resultados del proceso son (I) una versión actualizada de la metacolección OpenCitations que también incluye los metadatos de las entidades bibliográficas proporcionadas por la nueva fuente, y (II) una colección de datos de procedencia. Una base de datos interna se actualiza constantemente para preservar la correspondencia entre los ID y los OMID internos asociados.
PASO 2: Partiendo de la colección de citas expresadas como enlaces direccionales entre identificadores potencialmente de cualquier tipo (por ejemplo, DOI-DOI, PMID-PMID, PMC-PMID, etc.), el software INDEX consulta la base de datos interna que asigna los ID a los OMID para producir una versión actualizada del Índice OpenCitations: citas únicas expresadas como enlaces OMID-OMID en diferentes formatos, acompañadas de sus correspondientes datos de procedencia.

Fig. 1: Visión general del flujo de trabajo de ingestión de datos, comenzando por la conversión específica de la fuente de datos y la producción de citas y tablas de metadatos bibliográficos, pasando por el proceso META y la asignación de un identificador OMID a cada registro bibliográfico implicado en una cita, y culminando con la exposición de la colección del Índice OpenCitations de citas únicas OMID-OMID.
Lo que tenemos ahora The OpenCitations Index - El Índice OpenCitations
A partir de ahora, OpenCitations ya no mostrará un índice de datos de citas para cada fuente. En su lugar, publicaremos una única colección de citas en la que confluirán las contribuciones de cada una de las fuentes, a la que llamaremos simplemente "The OpenCitations Index". La primera versión de este índice unificado de citas OMID-OMID está publicada en Figshare. Se ha elaborado en formatos RDF, CSV y SCHOLIX, junto con una recopilación de su información de procedencia, proporcionada en formatos RDF y CSV. Para cada cita, es posible rastrear la fuente de la información consultando la colección de datos de Procedencia, gracias a la propiedad http://www.w3.org/ns/prov#atLocation, que define la ubicación de cada cita.
Esta nueva solución tiene la ventaja de simplificar la consulta de los datos mantenidos por nuestra infraestructura sin reducir el contenido de la información. Además, al incluir una gestión eficaz del problema de la deduplicación, el nuevo Índice no sólo proporciona datos precisos sobre el número exacto de citas únicas expuestas por el marco, sino que también verifica la contribución individual de cada fuente, así como sus datos superpuestos (Fig. 2).

Fig. 2: Visión general del número de citas almacenadas en el Índice OpenCitations a 31 de octubre de 2023. Las celdas diagonales de la tabla (resaltadas en amarillo) muestran la contribución única de cada colección al Índice OpenCitations, mientras que las demás celdas representan las citas que comparten las colecciones. Más en detalle, las celdas verdes muestran la aportación global de cada fuente, mientras que las rosas representan el número de citas que se solapan entre dos fuentes de datos.
Actualmente, el Índice contiene casi 2.000 millones de citas únicas. A finales de noviembre se publicará una nueva versión de la colección, que incluirá la aportación de la nueva fuente Japan Link Centre (JaLC).
Cómo acceder a los datos del The OpenCitations Index
Para maximizar la reutilización de la información expuesta y garantizar la mayor interoperabilidad posible, la colección se publicará siempre en Figshare en todos los formatos indicados anteriormente. Además, se podrá acceder a los datos a través de una API, un punto final SPARQL y una interfaz web.
El rediseño del flujo de trabajo de ingestión marca un paso fundamental para OpenCitations hacia un acceso más intuitivo y sencillo a nuestros servicios, preservando y mejorando siempre la calidad de nuestros datos. Si necesita más información sobre cómo funciona el nuevo flujo de trabajo, visite nuestro sitio web, póngase en contacto con nosotros en contact@opencitations.net o deje sus comentarios y/o sugerencias en la tarjeta dedicada a ello en nuestra hoja de ruta pública para ayudarnos a mejorar nuestros servicios y comunicaciones. Muchas gracias.
Cite este artículo como: Chiara Di Giambattista, "Un nuevo flujo de trabajo revolucionario para una recopilación unificada de citas: saluda al índice OpenCitations", en OpenCitations blog, 27/11/2023, https://opencitations.hypotheses.org/3499.
*******************************
A new revolutionary workflow for a unified collection of citations: say hello to the OpenCitations Index
Blog post by Ivan Heibi (University of Bologna), Arianna Moretti (University of Bologna) and Chiara Di Giambattista (University of Bologna).
In the past five years, the OpenCitations data has been enriched with numerous new indexes of open citation data from different sources. However, the quantity and diversification of the ingested information have raised several issues, which recently made it essential to conduct a complete revision of the ingestion workflow. The result was a revolution in the way OpenCitations data is delivered. In this blog post, we will explain the context and challenges raised by the old procedure. Then, we will present the new ingestion workflow, designed to produce just two comprehensive collections: OpenCitations Index, collecting open citation data, and OpenCitations Meta, for the open bibliographical metadata.
Once upon a time, there were five OpenCitations indexes…In 2018, OpenCitations released the kickoff version of its first citation index, COCI (citations from Crossref), which contained around 300 million citation links derived from the subset of the reference lists in the Crossref database, where citing and cited entities were identified using Digital Object Identifiers (DOIs). COCI gathered citations with associated metadata in compliance with the recommendations from the Initiative for Open Citations (I4OC) that citation data should be structured, separable, and open, thus marking a turning point by providing a disruptive and free and open alternative to earlier sources such as Google Scholar, which provided freely accessible data although not downloadable, and Web of Science or Scopus, which demanded paid access.
In a short time, COCI became a competitive and trusted index of citation data, used by numerous institutional repositories, including B!son and Optimeta. In 2021, COCI was taken into account in a comparative study with the most relevant sources in the landscape, including the proprietary ones, which showed its coverage approaching parity with those of the other sources involved in the analysis (Microsoft Academic, Scopus, Dimensions, and Web of Science). At the time of its most recent update in January 2023, COCI counted more than 1.4 billion citations. The reason behind this outstanding number lies in several factors, including Elsevier’s endorsement of the Declaration on Research Assessment (DORA) in December 2020, leading to the open release via Crossref of the reference lists of the articles published in all its journals, and confirming the value of initiatives such as the Initiative for Open Citations (I4OC).
However, before this change of heart, in 2019 OpenCitations had tried to narrow the open citations coverage gap by launching its second index, the Crowdsourced Open Citations Index (CROCI). This index allowed publishers and scholars to contribute directly by uploading crowdsourced open citations into the OpenCitations infrastructure.
In December 2022, a new concrete step towards a factual plurality of OpenCitations indexes was taken by the ingestion of new data sources into the infrastructure, with the publication of the inaugural dumps of DOCI (citations from DataCite) and POCI (citations from PubMed). In June 2023, the first version of the OROCI (citations from OpenAIRE) dump was released too, and JOCI (citations from JALC) is expected to be available by the end of November 2023, for a total of five collections from different sources.
Why a new workflow? The issues with multiple sources management and new challengesWhile having such a variety and richness of indexes helped present the extent of OpenCitations sources, the recent increment in the number of sources and the diversification of data integrated led to two primary issues:
the necessity to handle the ingestion of new identifier types in a DOI-based software infrastructure, and
the consequent possibility of encountering the same citation expressed by several sources with different identifiers.
Moreover, it soon became evident the need to optimize the reuse of the already developed software components to facilitate the metadata crosswalk processes between the new sources’ data models and the OpenCitations Data Model, with the aim to define a functional and easily extendable workflow to be easily reused when it comes to incorporating new data sources, which should be:
sufficiently generic to establish a globally unique procedure;
customizable enough to capture the necessary information within each of the specific data models and formats.
As a solution, we decided to use OpenCitations Meta, the new OpenCitations database and tool for managing bibliographic data related to the publications involved in the citations. OpenCitations Meta makes it possible to assign each entity involved in a citation an internal identifier, nominally the OpenCitations Meta Identifier (OMID), to which all the associated persistent identifiers of the same publication are redirected.
As a result, the allocation of an OMID for each bibliographic resource also enabled the unambiguous identification of each citation, regardless of the persistent identifier schema originally used by the data source to identify the resources. This approach allowed us to perform data deduplication and finally make all the sources’ contributions converge into a unified index containing all the unique citations managed by OpenCitations, expressed as OMID to OMID citation links.
The revised workflowThe new workflow is based on three main components with the benefit of optimizing the process both in terms of computational cost and in terms of flexibility. As shown in Fig. 1, in a preliminary step, source-specific software converts the input dataset – structured according to the source data model – to extract two OpenCitations Data Model compliant data collections in tabular format for bibliographic metadata and citation data, respectively.
The following steps are common to the process of each dataset.
STEP 1: The bibliographic metadata collection is used as input for the META software. At this stage, it is checked whether or not the bibliographic entities have been previously integrated into our infrastructure (coming from other data sources). If so, the existing OMID is linked also to the new alternative identifiers of the new bibliographic resources. New metadata values, if any, are also integrated. A new OMID identifier is produced for entities never previously encountered, uniquely representing the bibliographic resource in OpenCitations. The outputs of the process are: (I) an updated version of the OpenCitations Meta collection that also includes the metadata of the bibliographic entities provided by the new source, and (II) a collection of provenance data. An internal database is constantly refreshed to preserve correspondence between IDs and the associated internal OMIDs.
STEP 2: Starting from the collection of citations expressed as directional links between identifiers of potentially any type (e.g., DOI-DOI, PMID-PMID, PMC-PMID, etc.), the INDEX software queries the internal database mapping IDs to OMIDs to produce an updated version of the OpenCitations Index: unique citations expressed as OMID-OMID links in different formats, accompanied by their corresponding provenance data.
Fig. 1: An overview of the data ingestion workflow, starting from the data source-specific conversion and production of citations and bibliographic metadata tables, progressing through the META process and the assignation of an OMID identifier to each bibliographic record involved in a citation, and culminating with the exposition of the OpenCitations Index collection of OMID-OMID unique citations.
What we have now: The OpenCitations Index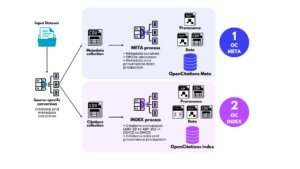
From now on, OpenCitations will no longer display an index of citation data for each source. Instead, we will publish a single collection of citations into which the contributions from each of the sources will flow, which we will simply call ‘The OpenCitations Index‘. The first version of this unified index of OMID-OMID citations is posted on Figshare. It was produced in RDF, CSV, and SCHOLIX formats, together with a collection of its provenance information, provided in RDF and CSV formats. For each citation, it is possible to trace the source of the information by consulting the Provenance data collection, thanks to the http://www.w3.org/ns/prov#atLocation property, which defines the location of each citation.
This new solution has the benefit of simplifying the consultation of the data maintained by our infrastructure without reducing the information content. In addition, by including efficient handling of the deduplication problem, the new Index not only provides accurate data on the exact number of unique citations exposed by the framework but also verifies the individual contribution of each source, as well as their overlapping data (Fig. 2). here**

Fig. 2: An overview of the number of citations stored in the OpenCitations Index as of October 31, 2023. The diagonal cells in the table (highlighted in yellow) show the unique contribution of each collection to the OpenCitations Index, while the other cells represent the citations that are shared between the collections. More in detail, the green cells show the overall input of each source, while the pink cells represent the number of overlapping citations between two data sources.
Currently, the Index contains almost 2 billion unique citations. By the end of November, a new version of the collection will be published, including the contribution of the new Japan Link Centre (JaLC) source.
How to access the OpenCitations Index dataTo maximize the reuse of the exposed information and to ensure the greatest possible interoperability, the collection will always be published on Figshare in all formats listed above. In addition, the data will be accessible via an API, a SPARQL endpoint, and a web interface.
The redesign of the ingestion workflow marks a fundamental step for OpenCitations towards a more intuitive and simple access to our services while always preserving and improving the quality of our data. If you need further information on how the new workflow works, please visit our website, contact us at contact@opencitations.net or leave feedback and/or suggestions in the dedicated card on our public roadmap to help us improve our services and communications. Thank you!
Cite this article as: Chiara Di Giambattista, "A new revolutionary workflow for a unified collection of citations: say hello to the OpenCitations Index," in OpenCitations blog, 27/11/2023, https://opencitations.hypotheses.org/3499.


