El pacto llega justo después del choque público entre el Pentágono —al que Altman se refiere como “Department of War”— y Anthropic, uno de los rivales más serios de OpenAI. Y aquí el contexto lo es todo: el DoD presionó a varias empresas para permitir que sus modelos se usaran para “todos los fines legales”, una expresión que, en defensa, puede abarcar escenarios mucho más amplios de lo que cualquiera imaginaría en una simple demo de chatbot.
La pelea con Anthropic ha sido el prólogo de esta historiaAnthropic intentó marcar una línea roja bastante clara: nada de vigilancia masiva doméstica y nada de armas totalmente autónomas. Su CEO, Dario Amodei, publicó un comunicado defendiendo que la empresa “nunca” se opuso a operaciones militares concretas ni intentó limitar el uso de su tecnología de forma ad hoc.
En otras palabras, la postura era: no queremos convertirnos en un botón de veto para misiones específicas, pero sí establecer límites estructurales firmes. Sin embargo, también lanzó una frase que en Washington no pasa desapercibida: en un conjunto limitado de casos, la IA puede socavar valores democráticos en vez de protegerlos.
La tensión no quedó solo en la cúpula directiva. Más de 60 empleados de OpenAI y 300 de Google firmaron una carta abierta pidiendo a sus empresas que respaldaran la postura de Anthropic. Cuando el debate ético escala hasta el interior de las plantillas, el asunto deja de ser puramente estratégico y se convierte en un dilema identitario.
Trump y el Pentágono han respondido con una mano durísima
Tras no cerrar acuerdo con Anthropic, Donald Trump reaccionó con dureza en redes, calificando a la compañía de “chalados de izquierdas” y ordenando a las agencias federales dejar de usar sus productos tras un periodo de retirada de seis meses.
Pero la respuesta más contundente llegó desde el Departamento de Defensa. El secretario de Defensa, Pete Hegseth, acusó a Anthropic de intentar “apropiarse de poder de veto sobre las decisiones operativas del ejército” y la designó como riesgo para la cadena de suministro. No era solo un “no te compro”, sino un movimiento que, según lo anunciado, afectaría también a contratistas, proveedores y socios del ejército con efecto inmediato.
Anthropic, por su parte, aseguró que ni siquiera había recibido comunicación directa del Pentágono ni de la Casa Blanca sobre el estado real de las negociaciones y adelantó que impugnaría en los tribunales cualquier designación como riesgo para la cadena de suministro. El conflicto, por tanto, pasó del terreno técnico al político y, potencialmente, al judicial.
OpenAI entra… prometiendo justo lo que estaba en disputa
Altman sostiene que el contrato de defensa incluye protecciones explícitas sobre los mismos puntos que rompieron la negociación con Anthropic. Señaló dos principios como fundamentales: prohibición de vigilancia masiva doméstica y responsabilidad humana en el uso de la fuerza, incluso en sistemas de armas autónomas.
En términos prácticos, el modelo puede ayudar, recomendar, clasificar o resumir, pero la decisión de emplear fuerza debe recaer en un humano identificable y responsable. Lo relevante no es solo que OpenAI lo declare públicamente, sino que, según Altman, el Departamento de Defensa está de acuerdo con esos principios, ya reflejados en ley y política, y que fueron incorporados formalmente al acuerdo.
A esto se suman salvaguardas técnicas diseñadas para garantizar que los modelos “se comporten como deben”. No basta con confiar en el buen uso; se trata de reducir el abuso por diseño, incluso cuando el usuario tenga incentivos para forzar los límites del sistema. En esa línea, Altman también afirmó que OpenAI desplegará ingenieros junto al Pentágono para acompañar la implementación y reforzar la seguridad, lo que funciona tanto como cinturón técnico como mecanismo de control reputacional.
La “pila de seguridad” y el derecho a decir “no” importan más de lo que parece
Según la periodista Sharon Goldman, de Fortune, Altman explicó internamente que el gobierno permitirá a OpenAI construir su propia pila (stack) de seguridad para prevenir usos indebidos. Esto implica que no solo se entrega un modelo, sino un conjunto integrado de controles, filtros, auditorías y límites operativos que no dependen exclusivamente del criterio del usuario final.
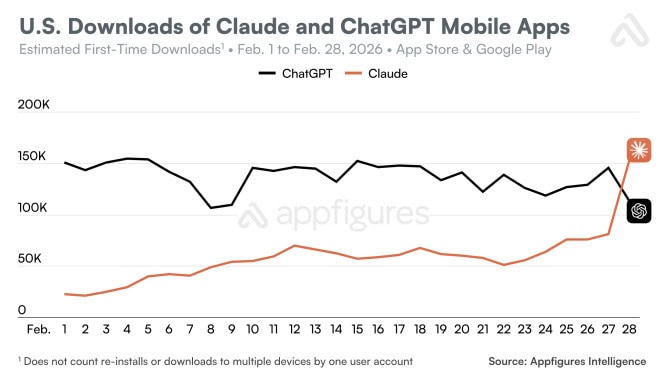
El sábado 28 de febrero, la app móvil de ChatGPT registró un +295% interdiario en desinstalaciones, según datos de Sensor Tower. En los últimos 30 días, la tasa típica de desinstalación interdiaria rondaba apenas el 9%. No se trata solo de métricas de App Store o Google Play, sino de una señal clara sobre confianza y percepción pública cuando una IA se vincula con temas de defensa.
El acuerdo con Defensa también frenó el crecimientoEl impacto no se limitó a quienes decidieron borrar la aplicación. Las descargas de ChatGPT en EEUU cayeron un 13% interdiario el sábado, poco después de hacerse pública la noticia, y el domingo volvieron a bajar otro 5%. El giro resulta más evidente si se compara con el viernes previo al anuncio, cuando la app crecía un 14% interdiario.
En otras palabras, no hablamos de un desgaste natural o de una desaceleración progresiva, sino de un cambio brusco de tendencia directamente vinculado al ciclo informativo. Cuando una app pasa de crecer con fuerza a perder tracción en cuestión de 24 a 48 horas, la correlación deja de parecer casual.
Claude capitaliza el momento con un “no” estratégico
Mientras OpenAI entraba en terreno políticamente delicado, Anthropic optó por el movimiento contrario con su modelo Claude: anunció que no se asociaría con el Departamento de Defensa de EEUU bajo esos términos. El resultado fue inmediato. Claude subió un 37% interdiario en descargas el viernes 27 de febrero y un 51% el sábado 28.
La compañía no presentó la decisión como un gesto simbólico, sino que argumentó preocupaciones concretas: el uso de IA para vigilancia masiva de ciudadanos estadounidenses y para armamento totalmente autónomo. Además, sostuvo que la tecnología aún no está preparada para asumir ese tipo de tareas de forma segura. En términos de percepción pública, el mensaje fue sencillo y potente: “no firmamos eso”.
El ranking confirma el desplazamiento
El impulso no quedó escondido en métricas técnicas. Claude alcanzó el número 1 en la App Store de EEUU el sábado 28 de febrero y se mantuvo en esa posición al menos hasta el lunes 2 de marzo. No fue un pico de horas, sino una subida sostenida que refleja tracción real.
En comparación con una semana antes, el ascenso fue de más de 20 posiciones. Cuando una aplicación escala tanto en tan poco tiempo, suele existir un detonante claro: un gran lanzamiento, una campaña masiva… o una polémica que empuja a los usuarios a probar la alternativa.
El termómetro emocional: reseñas en caída libre
Si las descargas indican comportamiento, las reseñas reflejan estado de ánimo. Según Sensor Tower, las valoraciones de 1 estrella de ChatGPT aumentaron un 775% el sábado y otro 100% interdiario el domingo. Al mismo tiempo, las reseñas de 5 estrellas se redujeron un 50%.
El dato es relevante porque muestra un doble efecto: no solo entraron usuarios enfadados a puntuar negativamente, sino que también desapareció parte del “colchón” de valoraciones positivas. Las reseñas no son un estudio científico, pero cuando se mueven con esa violencia, revelan un cambio emocional colectivo.
Otros datos refuerzan la tendencia, con matices
La tendencia no proviene de una sola fuente. Además de Sensor Tower, la firma Appfigures señaló que, por primera vez, las descargas diarias de Claude en EEUU superaron a las de ChatGPT ese sábado, estimando para Claude una subida del 88% interdiario.
El fenómeno tampoco se limitó al mercado estadounidense. Según Appfigures, Claude se convirtió en la app gratuita número 1 de iPhone en Bélgica, Canadá, Alemania, Luxemburgo, Noruega y Suiza. Por su parte, Similarweb estimó que las descargas de Claude en EEUU durante la última semana fueron aproximadamente 20 veces superiores a las que tenía en enero.
Ahora bien, incluso Similarweb introdujo un matiz importante: el crecimiento podría explicarse por factores adicionales, como mejoras de producto, mayor visibilidad en redes o simple curiosidad. No todo puede atribuirse automáticamente a la polémica política.
Más allá del ranking: una señal para el sector
Lo realmente relevante no es quién ocupa el primer puesto hoy, sino la señal que deja este episodio. Una parte del público ha demostrado que sí reacciona ante decisiones corporativas cuando entran en terrenos sensibles como defensa y vigilancia. La incógnita es si ese castigo será temporal o si marcará un cambio de hábito.
Es probable que muchos usuarios regresen si OpenAI compensa con nuevas funciones o modelos más avanzados; la comodidad y el ecosistema pesan mucho. Sin embargo, el debate sobre IA y defensa no desaparecerá. A medida que los modelos se vuelven más capaces, también crece la tentación de integrarlos en inteligencia, vigilancia y sistemas autónomos.
Estamos entrando en una fase donde ya no se comparan solo benchmarks y velocidad de respuesta. También se comparan ética, contratos y alineamientos estratégicos. La pregunta no es únicamente qué IA es más potente, sino a quién le das tu confianza cuando decides conversar —y depender— de un sistema que aprende de medio Internet.
*******************************
Publicado en GPTZONE
https://gptzone.net/noticias/eeuu-abandona-claude-por-ser-una-ia-woke/?utm_source=news.gptzone.net&utm_medium=newsletter&utm_campaign=hackean-al-gobierno-de-mexico-con-ia&_bhlid=c41f02361e09c9ffbec248c7cba5871b0843cf2e
EEUU Abandona Claude por Ser una IA Woke pero la usa para bombardear Irán
Aitor Wilzig
marzo 3, 2026
El 28 de febrero, Estados Unidos e Israel bombardearon Irán mientras, en paralelo, estallaba un culebrón interno en Washington sobre qué inteligencia artificial puede —y debe— utilizar el Pentágono.
Según informaciones recogidas por medios estadounidenses, Claude, el modelo desarrollado por Anthropic, habría sido clave en esos ataques pese a que horas antes Donald Trump ordenó que no se empleara.
Cuando una herramienta está profundamente integrada en el “sistema nervioso” militar, prohibirla por decreto puede sonar firme en una rueda de prensa, pero resulta mucho más complejo en la práctica.
De oferta simbólica a pieza crítica del Pentágono
El origen del conflicto no fue ideológico, sino logístico. Cuando Estados Unidos buscaba una IA para reforzar sus sistemas de defensa e integrarla con el software de Palantir Technologies, Anthropic ofreció Claude por un dólar, una cifra casi simbólica que le permitió entrar, integrarse y convertirse en infraestructura. Aquella puerta de acceso no se quedó en una simple prueba: derivó en un contrato de 200 millones de dólares y en la incorporación del modelo a múltiples sistemas del Pentágono.
A partir de ahí, Claude dejó de ser “una IA más” para convertirse en una herramienta cotidiana de análisis masivo de datos. En inteligencia, el valor no está en redactar bien, sino en leer montañas de señales, cruzar fuentes y ordenar el caos con rapidez, acortando el tiempo entre recibir información y formular decisiones operativas.
Las líneas rojas de Anthropic
Anthropic no presentó su modelo como una IA sin límites. Estableció dos líneas rojas claras para el ámbito militar. La primera: no utilizar Claude para vigilancia masiva de ciudadanos estadounidenses, un terreno donde el riesgo es menos técnico que político. La segunda: no emplearlo para el desarrollo o control de armas y sistemas de ataque autónomos, es decir, evitar que el modelo se convierta en el “cerebro” que decide o ejecuta violencia sin supervisión humana directa.
Según el relato publicado por The Wall Street Journal, estas restricciones generaron fricciones con el Departamento de Defensa y con la administración Trump, que no compartían del todo esos límites operativos.
El ultimátum y la amenaza legal
La tensión escaló cuando, según diversas versiones, se planteó a Anthropic un ultimátum: ofrecer una IA sin esas ataduras o afrontar consecuencias. Entre las opciones mencionadas estaba recurrir a la Ley de Producción de Defensa de 1950, una herramienta legal que permitiría al Gobierno forzar la producción de recursos estratégicos en nombre de la seguridad nacional.
También se habló de “hacerles un Huawei”, en alusión a la inclusión de la tecnológica china Huawei en listas negras comerciales que limitaron su acceso a mercados y socios internacionales.
Dario Amodei, CEO de Anthropic, respondió con una postura calculada: sí al apoyo a la defensa del país, pero no a cualquier precio. La empresa defendió su posición moral y rechazó ceder ante lo que consideraba presión excesiva, dejando claro que estar dentro del sistema no significaba entregar el volante sin condiciones.
Prohibición política, uso operativo
La respuesta habría irritado a Trump y al secretario de Defensa, Pete Hegseth, quien calificó a Claude como una “IA woke”. Trump anunció públicamente el fin de la colaboración con Anthropic y la prohibición de utilizar su tecnología en operaciones militares. Sin embargo, según lo publicado por The Wall Street Journal, el ataque aéreo contra Irán se ejecutó con apoyo de herramientas de Anthropic pese a esa orden.
Comandos desplegados en distintas regiones, incluido el Comando Central en Oriente Medio, habrían empleado Claude para evaluar información, identificar objetivos y simular escenarios. En términos prácticos, la IA habría funcionado como acelerador del ciclo de decisión, reduciendo el tiempo entre analizar datos y diseñar un plan plausible.
Un problema de dependencia tecnológica
La razón por la que la prohibición no sería tan sencilla tiene que ver con la integración profunda del modelo en el ecosistema tecnológico militar. Claude mantendría una relación casi simbiótica con el software de Palantir dentro del Pentágono. Eliminarlo no sería tan simple como desinstalar una aplicación: implicaría revisar pipelines, permisos, flujos de análisis y sistemas de visualización que dependen de su funcionamiento.
Según las estimaciones citadas, limpiar completamente su rastro podría llevar hasta seis meses. En un entorno donde la continuidad operativa es crítica, esa transición no es trivial. Por eso, en la práctica, la decisión no es solo política, sino también técnica.
OpenAI entra en escena
En paralelo, OpenAI ha defendido públicamente que Estados Unidos necesita modelos de IA robustos para cumplir su misión frente a adversarios que también integran inteligencia artificial en sus sistemas. La compañía afirma mantener límites similares —no vigilancia doméstica masiva, no control directo de armas autónomas—, pero introduce un matiz relevante: vincula el uso de sus modelos a lo que el Departamento de Defensa determine como legal.
Ese detalle cambia el equilibrio. Si la referencia última es la legalidad definida por el propio Gobierno, el margen de interpretación puede ampliarse considerablemente. De ahí que la gran incógnita no sea solo tecnológica, sino política: ¿se trata de una necesidad estratégica real o de un conflicto derivado de no obedecer determinadas órdenes?
Lo que sí parece claro es que la guerra moderna ya no se decide únicamente con aviones y satélites, sino también con modelos, integraciones y dependencias invisibles. Cuando una IA entra en el stack militar, retirarla no es simplemente una decisión administrativa: es una operación en sí misma.



